Tema 5: Tratamiento de Datos en MySQL
En este tema trabajaremos los siguientes RAs:
RA 4: Modifica la información almacenada utilizando herramientas gráficas y DML
Objetivo del tema:
Dominar DML y subconsultas como tablas derivadas y joins complejos. Estudiar los sistemas transacionales y la integridad ACID.
| **RA 4: Modifica la información almacenada utilizando herramientas gráficas y DML |
|---|
| a) |
1. Introducción
Contexto Empresarial:
Ada revisa el módulo de estadísticas avanzadas. Juan necesita implementar:
- Análisis multi-tabla: Rankings cruzando usuarios, partidas y juegos
- Actualizaciones masivas: Ajustar créditos basándose en subtotales calculados
- Integridad transaccional: Transferencias atómicas de crédito entre usuarios
- Concurrencia: Múltiples usuarios simultáneos sin corrupción de datos
Las bases de datos no tienen razón de ser sin la posibilidad de hacer operaciones para el tratamiento de la información almacenada en ellas. Por operaciones de tratamiento de datos se deben entender las acciones que permiten añadir información en ellas, modificarla o bien suprimirla.
En esta unidad podrás conocer que existen distintos medios para realizar el tratamiento de los datos. Desde la utilización de herramientas gráficas hasta el uso de instrucciones o sentencias del lenguaje SQL que permiten realizar ese tipo de operaciones de una forma menos visual pero con más detalle, flexibilidad y rapidez. El uso de unos mecanismos u otros dependerá de los medios disponibles y de nuestras necesidades como usuarios de la base de datos.
Pero la información no se puede almacenar en la base de datos sin tener en cuenta que debe seguir una serie de requisitos en las relaciones existentes entre las tablas que la componen. Todas las operaciones que se realicen respecto al tratamiento de los datos deben asegurar que las relaciones existentes entre ellos se cumplan correctamente en todo momento.
Por otro lado, la ejecución de las aplicaciones puede fallar en un momento dado y eso no debe impedir que la información almacenada sea incorrecta. O incluso el mismo usuario de las aplicaciones debe tener la posibilidad de cancelar una determinada operación y dicha cancelación no debe suponer un problema para que los datos almacenados se encuentren en un estado fiable.
Todo esto requiere disponer de una serie de herramientas que aseguren esa fiabilidad de la información, y que además puede ser consultada y manipulada en sistemas multiusuario sin que las acciones realizadas por un determinado usuario afecte negativamente a las operaciones de los demás usuarios.
2. Fundamentos del DML en MySQL
2.1. Operaciones Fundamentales
El lenguaje DML (Data Manipulation Language) opera sobre el modelo relacional mediante tres sentencias atómicas:
| Operación | Sintaxis Básica | Propósito |
|---|---|---|
| INSERT | INSERT INTO tabla (cols) VALUES (vals) | Crear registros |
| UPDATE | UPDATE tabla SET col=val WHERE cond | Modificar existentes |
| DELETE | DELETE FROM tabla WHERE cond | Eliminar registros |
Importante
Regla de Oro: Siempre ejecuta un SELECT con la misma cláusula WHERE antes de un UPDATE o DELETE para verificar el scope de filas afectadas.
2.2. Esquema de Trabajo: Jardinería Plus
Adaptación del esquema clásico con complejidad relacional aumentada:
📸 [INSERTAR CAPTURA PANTALLA 1: Diagrama ER del esquema en DBeaver]
2.3. La sentencia INSERT
La sentencia INSERT permite la inserción de nuevas filas o registros en un tabla existente. Según la documentación oficial de MySQL esta es la sintaxis de la sentencia INSERT en MySQL:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{VALUES | VALUE} (value_list) [, (value_list)] ...
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
SELECT ...
[ON DUPLICATE KEY UPDATE assignment_list]
value:
{expr | DEFAULT}
value_list:
value [, value] ...
assignment:
col_name = value
assignment_list:
assignment [, assignment] ...El formato más sencillo de utilización de la sentencia INSERT tiene la siguiente sintaxis:
INSERT INTO nombre_tabla (lista_campos) VALUES (lista_valores);Donde:
- nombre_tabla será el nombre de la tabla en la que quieras añadir nuevos registros.
- En lista_campos se indicarán los campos de dicha tabla en los que se desea escribir los nuevos valores indicados en lista_valores. Es posible omitir la lista de campos (lista_campos), si se indican todos los valores de cada campo y en el orden en el que se encuentran en la tabla.
- Tanto la lista de campos lista_campos como la de valores lista_valores, tendrán separados por comas cada uno de sus elementos.
- Hay que tener en cuenta también que cada campo de lista_campos debe tener un valor válido en la posición correspondiente de la lista_valores (Si no recuerdas los valores válidos para cada campo puedes utilizar la sentencia
*DESCRIBE*seguida del nombre de la tabla que deseas consultar).
Para poder probar los ejemplos debes tener creadas y cargadas las tablas de JuegosOnline en el usuario c##juegos o similar. Si no lo has hecho en la unidad anterior, descárgate el script de este enlace, conecta con sys as sysdba y a continuación ejecútalo. Recuerda que si lo haces desde sqlplus solo tienes que escribir la ruta y el nombre del script precedido del símbolo @ o bien de la palabra start.
Antes de ejecutar el siguiente ejemplo que inserta un nuevo registro en la tabla *USUARIOS* en el que se tienen todos los datos disponibles debes ejecutar la sentencia
**ALTER SESSION SET NLS_DATE_FORMAT='DD/MM/YYYY';**para que tome la fecha en ese formato en el que le estamos dando el dato fecha.
INSERT INTO USUARIOS (Login, Password, Nombre, Apellidos, Direccion, CP, Localidad, Provincia, Pais, F_Nac,
F_Ing, Correo, Credito, Sexo) VALUES ('migrod86', '6PX5=V', 'MIGUEL ANGEL', 'RODRIGUEZ RODRIGUEZ', 'ARCO DEL LADRILLO,PASEO',
'47001', 'VALLADOLID', 'VALLADOLID', 'ESPAÑA', '27/04/1977', '10/01/2008', 'migrod86@gmail.com', 200, 'H');En este otro ejemplo, se inserta un registro de igual manera, pero sin disponer de todos los datos:
INSERT INTO USUARIOS (Login, Password, Nombre, Apellidos, direccion,cp,localidad,provincia,pais,Correo) VALUES ('natsan63',
'VBROMI', 'NATALIA', 'SANCHEZ GARCIA','C/Blanca','28003','Madrid','Madrid','Spain', 'natsan63@hotmail.com');Al hacer un *INSERT* en el que no se especifiquen los valores de todos los campos, se obtendrá el valor *NULL* en aquellos campos que no se han indicado.
Si la lista de campos indicados no se corresponde con la lista de valores, o si no se proporcionan valores para campos que no admiten el valor NULL, se obtendrá un error en la ejecución. Por ejemplo, si no se indica el campo Apellidos pero sí se especifica un valor para dicho campo:
INSERT INTO USUARIOS (Login, Password, Nombre, Correo) VALUES ('caysan56', 'W4IN5U', 'CAYETANO', 'SANCHEZ CIRIZA', 'caysan56@gmail.com');
Se obtiene el siguiente error:
2.4. La sentencia UPDATE
La sentencia *UPDATE* permite modificar una serie de valores de determinados registros de las tablas de la base de datos.
La manera más sencilla de utilizar la sentencia *UPDATE* tiene la siguiente sintaxis:
UPDATE nombre_tabla SET nombre_campo = valor [, nombre_ campo = valor]...
[ WHERE condición ];Donde nombre_tabla será el nombre de la tabla en la que quieras modificar datos. Se pueden especificar los nombres de campos que se deseen de la tabla indicada. A cada campo especificado se le debe asociar el nuevo valor utilizando el signo =. Cada emparejamiento campo=valor debe separarse del siguiente utilizando comas (,).
La cláusula *WHERE* seguida de la condición es opcional (como pretenden indicar los corchetes). Si se indica, la actualización de los datos sólo afectará a los registros que cumplen la condición. Por tanto, ten en cuenta que si no indicas la cláusula *WHERE*, los cambios afectarán a todos los registros.
Por ejemplo, si se desea poner a 200 el crédito de todos los usuarios:
UPDATE USUARIOS SET Credito = 200;En este otro ejemplo puedes ver la actualización de dos campos, poniendo a 0 el crédito y poniendo a Nulos la información del campo f_nac de todos los usuarios:
UPDATE USUARIOS SET Credito = 0, f_nac = NULL;Para que los cambios afecten a determinados registros hay que especificar una condición. Por ejemplo, si se quiere cambiar el crédito de todas la mujeres, estableciendo el valor 300:
UPDATE USUARIOS SET Credito = 300 WHERE Sexo = 'M';Cuando termina la ejecución de una sentencia *UPDATE*, se muestra la cantidad de registros (filas) que han sido actualizadas, o el error correspondiente si se ha producido algún problema. Por ejemplo podríamos encontrarnos con un mensaje similar al siguiente:
9 fila(s) actualizada(s).
2.5. La sentencia DELETE
La sentencia *DELETE* es la que permite eliminar o borrar registros de un tabla.
Esta es la sintaxis que debes tener en cuenta para utilizarla:
DELETE FROM nombre_tabla [ WHERE condición ];Al igual que hemos visto en las sentencias anteriores, nombre_tabla hace referencia a la tabla sobre la que se hará la operación, en este caso de borrado. Se puede observar que la cláusula *WHERE* es opcional. Si no se indica, debes tener muy claro que se borrará todo el contenido de la tabla, aunque la tabla seguirá existiendo con la estructura que tenía hasta el momento.
Por ejemplo, si usas la siguiente sentencia, borrarás todos los registros de la tabla *USUARIOS*:
DELETE FROM USUARIOS;Es tan importante escribir la cláusula WHERE en la sentencia, si no quieres borrar la tabla entera, que incluso hay una canción que lo recuerda.. Puedes verla en este enlace.
Para ver un ejemplo de uso de la sentencia *DELETE* en la que se indique una condición, supongamos que queremos eliminar todos los usuarios cuyo crédito es cero:
DELETE FROM USUARIOS WHERE Credito = 0;Como resultado de la ejecución de este tipo de sentencia, se obtendrá un mensaje de error si se ha producido algún problema, o bien, el número de filas que se han eliminado.
2.5.1. Borrado y modificación de datos con integridad referencial
ON DELETE y ON UPDATE: Nos permiten indicar el efecto que provoca el borrado o la actualización de los datos que están referenciados por claves ajenas. Las opciones que podemos especificar son las siguientes:
- RESTRICT: Impide que se puedan actualizar o eliminar las filas que tienen valores referenciados por claves ajenas. Es la opción por defecto en MySQL.
- CASCADE: Permite actualizar o eliminar las filas que tienen valores referenciados por claves ajenas.
- SET NULL: Asigna el valor NULL a las filas que tienen valores referenciados por claves ajenas.
- NO ACTION: Es una palabra clave del estándar SQL. En MySQL es equivalente a RESTRICT.
- SET DEFAULT: No es posible utilizar esta opción cuando trabajamos con el motor de almacenamiento InnoDB. Puedes encontrar más información en la documentación oficial de MySQL.
3. Tratamiendo de datos con subconsultas como Tablas Derivadas (Derived Tables)
La técnica más potente para operaciones DML complejas consiste en tratar una consulta SELECT como una tabla virtual dentro de otra operación.
3.1. Sintaxis MySQL para Derived Tables
-- Estructura base
SELECT dt.columna1, dt.columna2
FROM (
SELECT columna_a, columna_b, funcion_agregada
FROM tabla_origen
WHERE condicion
GROUP BY columna_a
HAVING filtro_agregado
) AS dt
INNER JOIN otra_tabla ON dt.columna_a = otra_tabla.columna;Reglas MySQL específicas:
- Obligatorio usar alias (
AS dt) para la subconsulta - No se puede referenciar la derived table desde fuera de su scope
- Se materializa en memoria (o temp table si excede
tmp_table_size)
3.2. UPDATE Masivo con Derived Table
Escenario: Aumentar el límite de crédito de clientes basándose en el volumen de compras histórico.
UPDATE clientes c
INNER JOIN (
SELECT
p.codigo_cliente,
SUM(dp.cantidad * dp.precio_unidad) AS total_compras,
COUNT(DISTINCT p.codigo_pedido) AS num_pedidos
FROM pedidos p
INNER JOIN detalle_pedidos dp ON p.codigo_pedido = dp.codigo_pedido
WHERE p.estado = 'Entregado'
GROUP BY p.codigo_cliente
HAVING total_compras > 10000
) AS ventas ON c.codigo_cliente = ventas.codigo_cliente
SET c.limite_credito = c.limite_credito + (ventas.total_compras * 0.10);Flujo de ejecución:
- MySQL ejecuta la subconsulta (derived table
ventas) primero - Materializa los resultados: clientes con >10k€ en pedidos entregados
- Realiza el JOIN con la tabla
clientes - Actualiza solo las filas coincidentes
📸 [INSERTAR CAPTURA PANTALLA 2: Captura de DBeaver mostrando el resultado del UPDATE anterior con filas afectadas]
3.3. INSERT con SELECT complejo (CTAS - Create Table As Select)
Escenario: Crear tabla de histórico de clientes VIP basada en agregaciones.
-- Crear tabla y poblar en una operación
CREATE TABLE clientes_vip AS
SELECT
c.codigo_cliente,
c.nombre_cliente,
c.ciudad,
c.pais,
ventas.totales,
ventas.ultima_compra,
e.nombre AS nombre_rep,
e.email AS email_rep
FROM clientes c
INNER JOIN (
SELECT
codigo_cliente,
SUM(cantidad * precio_unidad) AS totales,
MAX(fecha_pedido) AS ultima_compra
FROM pedidos p
JOIN detalle_pedidos dp ON p.codigo_pedido = dp.codigo_pedido
GROUP BY codigo_cliente
HAVING totales > 5000
) AS ventas ON c.codigo_cliente = ventas.codigo_cliente
LEFT JOIN empleados e ON c.codigo_empleado_rep_ventas = e.codigo_empleado;
-- Añadir clave primaria a posteriori (MySQL requiere esto para InnoDB)
ALTER TABLE clientes_vip
ADD COLUMN id_vip INT AUTO_INCREMENT PRIMARY KEY,
ADD INDEX idx_ciudad (ciudad);📸 [INSERTAR CAPTURA PANTALLA 3: Estructura de tabla creada con CTAS en DBeaver]
4. Joins Complejos en Operaciones DML
MySQL permite utilizar JOINs en sentencias UPDATE y DELETE, pero con sintaxis específica diferente a PostgreSQL.
4.1. Tipos de JOIN en MySQL

Fuente: Wikipedia - SQL Joins (Dominio Público)
| Tipo | Descripción | Uso en DML |
|---|---|---|
| INNER JOIN | Solo filas coincidentes en ambas tablas | Actualizaciones sincronizadas |
| LEFT JOIN | Todas las filas de la izquierda, NULL si no hay match en derecha | Actualizaciones condicionales |
| RIGHT JOIN | Todas las filas de la derecha | Raro en DML, preferible reordenar |
| CROSS JOIN | Producto cartesiano | Generación de combinaciones |
4.2. UPDATE con múltiples JOINs
Sintaxis MySQL específica:
UPDATE tabla_destino t1
[INNER|LEFT] JOIN tabla_fuente t2 ON t1.col = t2.col
[INNER|LEFT] JOIN tabla_tercera t3 ON t2.col = t3.col
SET t1.columna = valor,
t2.columna = valor
WHERE condicion;Ejemplo práctico: Actualizar el estado de pedidos basándose en el total calculado y la ciudad del cliente.
UPDATE pedidos p
INNER JOIN (
SELECT
dp.codigo_pedido,
SUM(dp.cantidad * dp.precio_unidad) AS total_real
FROM detalle_pedidos dp
GROUP BY dp.codigo_pedido
) AS calculo ON p.codigo_pedido = calculo.codigo_pedido
INNER JOIN clientes c ON p.codigo_cliente = c.codigo_cliente
SET p.estado = CASE
WHEN calculo.total_real > c.limite_credito THEN 'Revision Crediticia'
WHEN calculo.total_real > 10000 THEN 'Urgente VIP'
ELSE p.estado
END,
p.comentarios = CONCAT(p.comentarios, ' | Total calculado: ', calculo.total_real)
WHERE p.estado = 'Pendiente';4.3. DELETE con JOIN: Eliminación Referencial
MySQL usa sintaxis diferente para DELETE con JOIN:
-- Sintaxis correcta MySQL para DELETE con JOIN
DELETE t1, t2 -- Especificar qué tablas eliminar (puede ser solo una)
FROM tabla1 t1
INNER JOIN tabla2 t2 ON t1.id = t2.id_tabla1
WHERE condicion;Escenario: Eliminar clientes sin pedidos y sus representantes asociados (ejemplo didáctico):
-- Eliminar solo clientes sin actividad
DELETE c
FROM clientes c
LEFT JOIN pedidos p ON c.codigo_cliente = p.codigo_cliente
WHERE p.codigo_pedido IS NULL
AND c.limite_credito = 0;🔥 Peligro: Si omites el alias después de
DELETE, MySQL eliminará de todas las tablas del JOIN.
5. Subconsultas Correlacionadas y No Correlacionadas
5.1. Subconsultas en SELECT (Columnas calculadas)
Útiles para evitar GROUP BY en la query principal:
SELECT
c.nombre_cliente,
c.ciudad,
c.limite_credito,
(SELECT COUNT(*)
FROM pedidos p
WHERE p.codigo_cliente = c.codigo_cliente) AS total_pedidos,
(SELECT COALESCE(SUM(dp.cantidad * dp.precio_unidad), 0)
FROM pedidos p
JOIN detalle_pedidos dp ON p.codigo_pedido = dp.codigo_pedido
WHERE p.codigo_cliente = c.codigo_cliente
AND p.estado = 'Entregado') AS valor_total_compras,
(SELECT MAX(fecha_pedido)
FROM pedidos p2
WHERE p2.codigo_cliente = c.codigo_cliente) AS ultima_compra
FROM clientes c
WHERE c.pais = 'España';Performance: MySQL materializa estas subconsultas una vez por fila de la outer query (correlacionadas). Para >1000 filas, considerar un JOIN con GROUP BY.
5.2. EXISTS vs IN: Optimización de Existencia
-- Anti-patrón IN (lento con subconsultas grandes)
SELECT * FROM clientes
WHERE codigo_cliente IN (
SELECT codigo_cliente
FROM pedidos
WHERE estado = 'Pendiente'
);
-- Optimización EXISTS (short-circuit evaluation)
SELECT c.*
FROM clientes c
WHERE EXISTS (
SELECT 1
FROM pedidos p
WHERE p.codigo_cliente = c.codigo_cliente
AND p.estado = 'Pendiente'
);Diferencia clave: EXISTS deja de buscar al encontrar la primera coincidencia; IN materializa toda la lista primero.
📸 [INSERTAR CAPTURA PANTALLA 4: Explain plan mostrando la diferencia de performance]
6. Transacciones y Control de Concurrencia en MySQL
6.1. Motor InnoDB y ACID
MySQL con motor InnoDB garantiza las propiedades ACID:
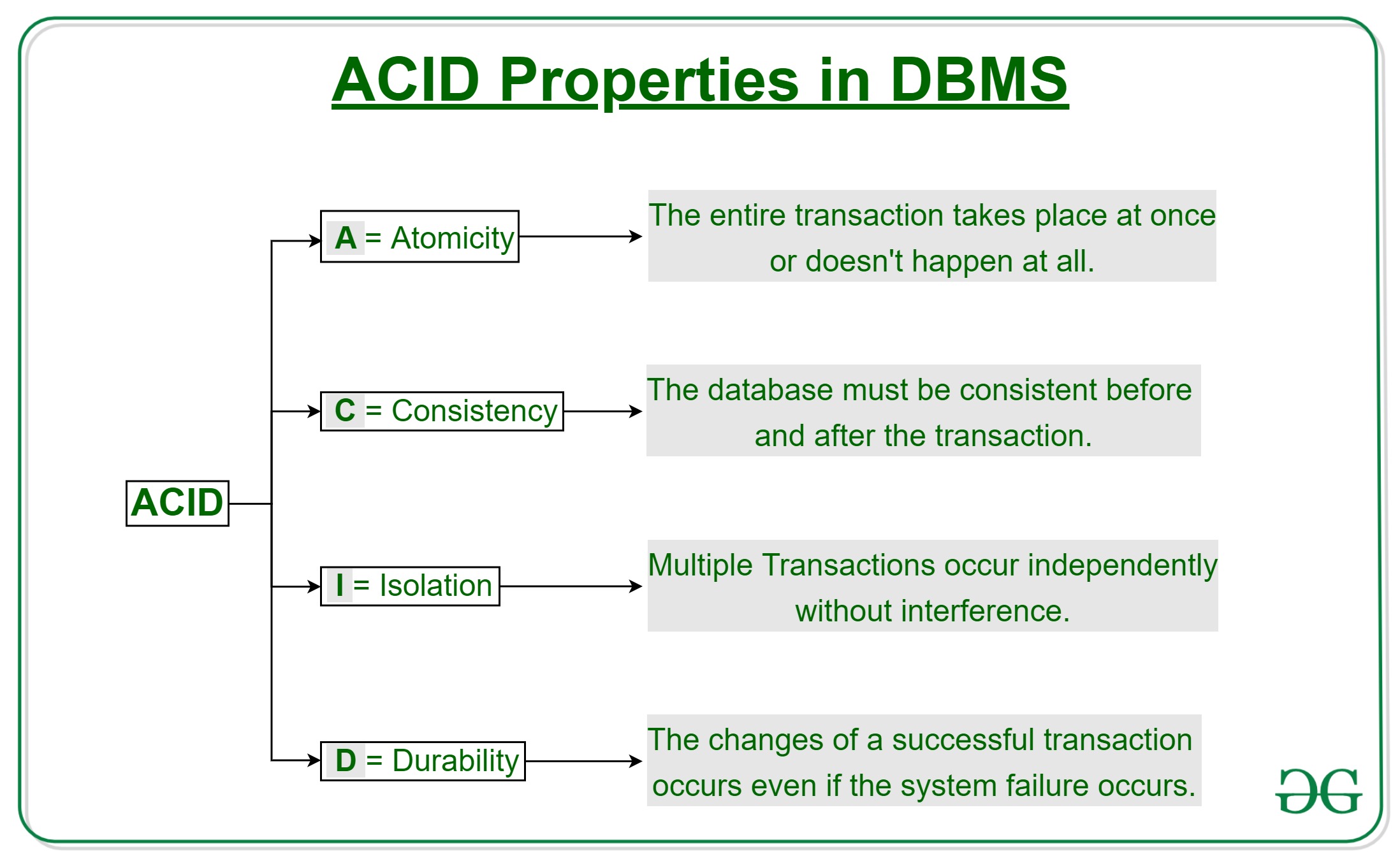
Fuente: GeeksforGeeks (Uso educativo)
-- Verificar motor de almacenamiento
SHOW TABLE STATUS WHERE Name = 'clientes';
-- Si fuera MyISAM (no soporta transacciones), convertir:
ALTER TABLE clientes ENGINE=InnoDB;6.2. Sintaxis de Transacciones MySQL
-- Iniciar transacción (tres formas equivalentes)
START TRANSACTION;
-- o
BEGIN;
-- o
BEGIN WORK;
-- Operaciones DML
INSERT INTO pedidos (...) VALUES (...);
SET @ultimo_pedido = LAST_INSERT_ID();
INSERT INTO detalle_pedidos VALUES (@ultimo_pedido, 'OR-001', 5, 100.00);
UPDATE productos SET stock = stock - 5 WHERE codigo_producto = 'OR-001';
-- Confirmar o revertir
COMMIT;
-- o
ROLLBACK;6.3. Niveles de Aislamiento

Fuente: SQL Nest (Uso educativo)
| Nivel | Dirty Read | Non-Repeatable | Phantom | Default en MySQL |
|---|---|---|---|---|
| READ UNCOMMITTED | Sí | Sí | Sí | No |
| READ COMMITTED | No | Sí | Sí | Oracle/PostgreSQL |
| REPEATABLE READ | No | No | Sí (parcial) | Sí (MySQL) |
| SERIALIZABLE | No | No | No | No |
-- Ver nivel actual
SELECT @@transaction_isolation;
-- Cambiar nivel (solo para siguiente sesión/transacción)
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN;
SELECT * FROM clientes WHERE codigo_cliente = 1;
-- Otra sesión modifica el cliente...
SELECT * FROM clientes WHERE codigo_cliente = 1; -- ¿Mismo resultado?
COMMIT;6.4. Savepoints (Puntos de Salvaguarda)
MySQL soporta rollback parcial mediante savepoints:
BEGIN;
INSERT INTO pedidos (codigo_cliente, fecha_pedido)
VALUES (1, CURDATE());
SET @pedido_id = LAST_INSERT_ID();
SAVEPOINT antes_detalle_1;
INSERT INTO detalle_pedidos VALUES (@pedido_id, 'PROD-001', 100, 50.00);
-- Verificar stock (simulado)
SELECT stock INTO @stock_actual FROM productos WHERE codigo_producto = 'PROD-001';
IF @stock_actual < 100 THEN
ROLLBACK TO SAVEPOINT antes_detalle_1;
-- Insertar línea alternativa o registrar error
INSERT INTO log_errores VALUES ('Stock insuficiente', NOW());
END IF;
-- Continuar con otros detalles
INSERT INTO detalle_pedidos VALUES (@pedido_id, 'PROD-002', 50, 30.00);
COMMIT;⚠️ Limitación: MySQL no permite usar variables de sesión directamente en procedimientos almacenados sin DECLARE. Para lógica compleja, usar Stored Procedures.
6.5. Bloqueos Explícitos (Locking)
-- Bloqueo pesimista de filas para actualización
BEGIN;
SELECT * FROM clientes
WHERE codigo_cliente = 1
FOR UPDATE; -- Bloquea la fila hasta COMMIT/ROLLBACK
-- Actualizar
UPDATE clientes SET limite_credito = limite_credito - 100 WHERE codigo_cliente = 1;
COMMIT; -- Libera el bloqueo7. Buenas Prácticas y Optimización MySQL
7.1. Checklist Seguro para Updates/Deletes
-- Paso 1: Previsualizar con SELECT
SELECT * FROM clientes
WHERE ciudad = 'Madrid'
AND limite_credito < 1000;
-- Paso 2: Ejecutar dentro de transacción reversible
BEGIN;
UPDATE clientes
SET limite_credito = limite_credito + 500
WHERE ciudad = 'Madrid'
AND limite_credito < 1000;
-- Paso 3: Verificar conteo de filas afectadas
SELECT ROW_COUNT(); -- MySQL devuelve número de filas modificadas
-- Paso 4: Confirmar o revertir
COMMIT;
-- o
ROLLBACK;7.2. INSERT ... ON DUPLICATE KEY UPDATE (Upsert)
MySQL soporta operaciones atómicas insert-or-update:
INSERT INTO clientes (codigo_cliente, nombre_cliente, ciudad, limite_credito)
VALUES (100, 'Cliente Nuevo', 'Barcelona', 5000)
ON DUPLICATE KEY UPDATE
nombre_cliente = VALUES(nombre_cliente),
ciudad = VALUES(ciudad),
limite_credito = limite_credito + VALUES(limite_credito);Requisito: Debe existir PRIMARY KEY o UNIQUE INDEX sobre codigo_cliente.
7.3. REPLACE INTO (Alternativa peligrosa)
REPLACE INTO clientes (codigo_cliente, nombre_cliente)
VALUES (1, 'Nuevo Nombre');⚠️ Cuidado:
REPLACEhace DELETE + INSERT, eliminando triggers y rompiendo foreign keys. PreferirINSERT ... ON DUPLICATE KEY UPDATE.
8. Ejercicios Prácticos
Ejercicio 1: Derived Tables (3 puntos)
Actualizar el salario de empleados (empleados.salario - añadir columna) basándose en el 5% del total de ventas de sus clientes. Usar una subconsulta en FROM para calcular las ventas por representante.
Solución esperada:
ALTER TABLE empleados ADD COLUMN salario DECIMAL(10,2) DEFAULT 2000;
UPDATE empleados e
INNER JOIN (
SELECT codigo_empleado_rep_ventas, SUM(cantidad * precio_unidad) * 0.05 AS comision
FROM clientes c
JOIN pedidos p ON c.codigo_cliente = p.codigo_cliente
JOIN detalle_pedidos dp ON p.codigo_pedido = dp.codigo_pedido
GROUP BY codigo_empleado_rep_ventas
) AS ventas ON e.codigo_empleado = ventas.codigo_empleado_rep_ventas
SET e.salario = e.salario + ventas.comision;Ejercicio 2: Delete con Join (2 puntos)
Eliminar todos los pedidos que no tengan detalles asociados (pedidos vacíos) y que tengan más de 6 meses de antigüedad.
Ejercicio 3: Transacción con Savepoint (3 puntos)
Crear un procedimiento (o script) que:
- Cree un pedido para el cliente 5 con fecha hoy
- Inserte dos líneas de detalle
- Si el producto 'OR-001' no tiene stock suficiente, rollback solo de esa línea pero mantener el pedido y la otra línea
- Confirmar al final
Ejercicio 4: Optimización (2 puntos)
Convertir la siguiente query correlacionada en una versión con JOIN + GROUP BY más eficiente:
-- Versión ineficiente (NO USAR)
SELECT c.nombre_cliente,
(SELECT COUNT(*) FROM pedidos WHERE codigo_cliente = c.codigo_cliente) as num
FROM clientes c;9. Referencias y Recursos
- Documentación MySQL: UPDATE Syntax, DELETE Syntax
- Imágenes:
- SQL Joins: Wikipedia (Dominio Público)
- ACID Properties: GeeksforGeeks (CC BY-SA)
- Isolation Levels: SQL Nest (Uso educativo)
- Dataset: MySQL Sample Database (Jardinería adaptada)
Licencia: Material adaptado para FP Superior - DAM/DAW bajo licencia Creative Commons BY-NC-SA 4.0